编译器工程师眼中的好代码(1):Loop Interchange
编者按:C/C++代码在编译时,编译器将源码翻译成 CPU 可识别的指令序列并生成可执行代码,而最终代码的运行效率取决于由编译器生成的可执行代码。在大部分情况下,编写源代码时就已经决定了程序可以在何种程度下被编译器优化。即使对源代码做微小改动也可能会对编译器生成的代码运行效率产生重大影响。因此,源代码的优化可以在一定程度上帮助编译器生成更高效的可执行代码。
本文将以 Loop Interchange 的场景为例,讲述在编写代码时可以拿到更优性能的书写方式。
1. Loop Interchange 相关基本概念
1.1 访问局部性
访问局部性指的是在计算机科学领域中应用程序在访问内存的时候,倾向于访问内存中较为靠近的值。这种局部性是出现在计算机系统中的一种可预测行为,我们可以利用系统的这种强访问局部性来进行性能优化。访问局部性分为三种基本形式,分别为时间局部性、空间局部性、循序局部性。
而本文主要讲述的 Loop Interchange 主要是利用了空间局部性。空间局部性指的是,最近引用过的内存位置以及其周边的内存位置容易再次被使用。比较常见于循环中,比如在一个数组中,如果第 3 个元素在上一个循环中被使用,那么本次循环中极有可能会使用第 4 个元素;如果本次循环确实使用第 4 个元素,就是命中上一次迭代所 prefetch 到的 cache 数据。
所以对于数组循环运算,可以利用空间局部性这一特征,保证两次相邻循环中对数组元素的访问在内存上是更加靠近的,即循环访问数组中的元素时 stride 越小,相应的性能可能会有所优化。
那么,数组在内存上是如何存储的呢?
1.2 Row-major 和 Column-major
Row-major 和 Column-major 是两种将多维数组存储在线性存储中的方式。数组的元素在内存中是连续的;Row-major ordering 代表行的连续元素在内存中彼此相邻,而 Column-major ordering 则是代表列的连续元素彼此相邻,如下图所示。
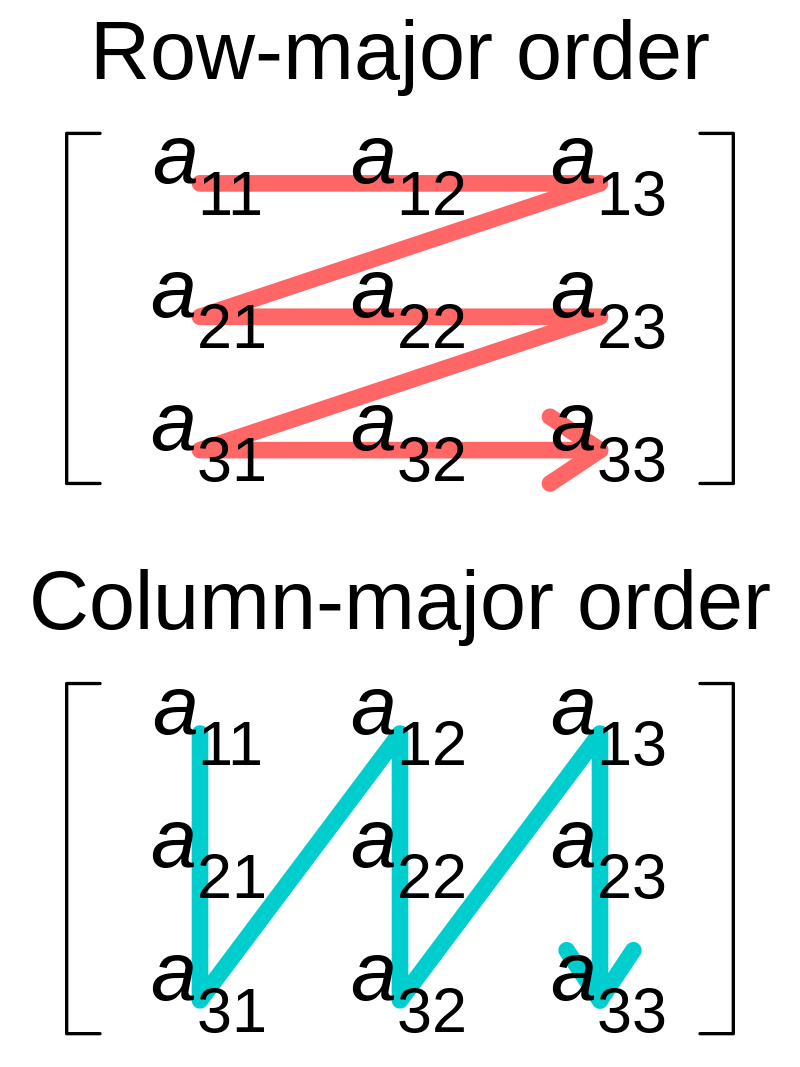
虽然 Row 和 Column 的名称看起来像是特指二维数组,但是 Row-major 和 Column-major 也可以推广适用于任何维度的数组。
那么在 C/C++中,数组是以以上哪种方式存储的呢?
举一个小例子,用 cachegrind 工具来展示 C 使用两种不同的访问形式的 CPU 的 cache 丢失率对比。
按行访问:
#include <stdio.h>
int main(){
size_t i,j;
const size_t dim = 1024 ;
int matrix [dim][dim];
for (i=0;i< dim; i++)
for (j=0;j <dim;j++)
matrix[i][j]= i*j;
return 0;
}
按列访问:
#include <stdio.h>
int main(){
size_t i,j;
const size_t dim = 1024 ;
int matrix [dim][dim];
for (i=0;i< dim; i++){
for (j=0;j <dim;j++){
matrix[j][i]= i*j;
}
}
return 0;
}
根据上述 C 代码中对相同数组的两种不同访问方式时 cache 丢失率的对比,可以说明在 C/C++代码中,数组是以 Row-major 形式储存的。也就是说,如果前一步访问了a[i][j],那么对a[i][j+1]的访问会命中 cache。这样就不会执行对主存储器的访问,而 cache 比主内存快,因此遵循相应编程语言的储存形式使其可以命中 cache 可能会带来优化。
至于其他常用的编程语言,Fortran、MATLAB 等则是默认 Column-major 形式。
1.3 Loop Interchange
Loop Interchange 利用系统倾向于访问内存中较为靠近的值的特征以及 C/C++ Row-major 的特点,通过改变循环嵌套中两个循环之间的执行顺序,增加整体代码空间局部性。此外,它还可以启用其他重要的代码转换,例如,Loop Reordering 就是 Loop Interchange 扩展到两个以上循环被重新排序时的优化。在 LLVM 中,Loop Interchange 需要通过使能-mllvm -enable-loopinterchange选项启用。
2. 优化示例
2.1 基础场景
简单看下面一个矩阵运算的示例:
原始代码:
for(int i = 0; i < 2048; i++) {
for(int j = 0; j < 1024; j++) {
for(int k = 0; k < 1024; k++) {
C[i * 1024 + j] += A[i * 1024 + k] * B[k * 1024 + j];
}
}
}试着把jk两层循环进行 Loop Interchange 之后的代码:
for(int i = 0; i < 2048; i++) {
for(int k = 0; k < 1024; k++) {
for(int j = 0; j < 1024; j++) {
C[i * 1024 + j] += A[i * 1024 + k] * B[k * 1024 + j];
}
}
}可以发现,在原始代码中,最内层的k每次迭代,C要访问的数据不变,A每次访问的 stride 为 1,大概率命中 cache,但B由于每次访问的 stride 为 1024,几乎每次都会 cache miss。Loop Interchange 之后,j位于最内层循环,每次迭代时A每次要访问的数据不变,C和B每次访问的 stride 为 1,都会有很大概率命中 cache,cache 命中率大大增加。
那么 cache 命中率是否真的增加,以及两者的性能又如何呢?
原始代码:
$ time -p ./a.out
$ sudo perf stat -r 3 -e cache-misses,cache-references,L1-dcache-load-misses,L1-dcache-loads ./a.out
Loop Interchange 后的结果如下:
$ time -p ./a.out
$ sudo perf stat -r 3 -e cache-misses,cache-references,L1-dcache-load-misses,L1-dcache-loads ./a.out
两者相比:
L1-dcache-loads 的数目差不多,因为要访问的数据总量差不多;
L1-dcache-load-misses 所占 L1-dcache-loads 的比例在进行 Loop Interchange 代码修改后降低了将近 10 倍。
同时,性能数据上也能带来接近 9.5%的性能提升。
2.2 特殊场景
当然,在实际使用时,并不是所有的场景都是如 2.1 中所示的那种工整的可 Loop Interchange 场景。
for ( int i = 0; i < N; ++ i )
{
if( I[i] != 1 ) continue;
for ( int m = 0; m < M; ++ m )
{
Res2 = res[m][i] * res[m][i];
norm[m] += Res2;
}
}如上述场景,如果 N 是超大数组,那么 Loop Interchange 理论上可以带来较大收益;但由于两层循环中间增加一个分支判断,导致原本可以 Loop Interchange 的场景无法实现。
针对这种场景,可以考虑将中间的分支判断逻辑剥离,可以先保证 Loop Interchange 使得数组res在连续内存上进行访问;至于中间的判断分支逻辑,可以在 Loop Interchange 两层循环后再进行回退。
for ( int m = 0; m < M; ++ m )
{
for ( int i = 0; i < N; ++ i)
{
Res2 = res[m][i] * res[m][i];
norm[m] += Res2;
if( I[i] != 1 ) //补充逻辑,保证源代码语义
{
norm[m] -= Res2;
continue;
}
}
}当然,这样的源码修改也需要考虑 cost 是否值得,如果该 if 分支进入频率非常高,那么之后回退带来的 cost 也会较大,可能就需要重新考虑 Loop Interchange 是否值得;反之,如果分支进入频率非常低,那么 Loop Interchange 的实现还是可以带来可观的收益的。
3. 毕昇编译器在 LLVM 社区的贡献
毕昇编译器团队在 LLVM 社区中对 Loop Interchange pass 也做出了不小的贡献。团队从 legality、profitability 等方面对 Loop Interchange pass 做了全方位的增强,同时也对该 pass 所支持的场景做了大量的扩展。在 Loop Interchange 方面,近两年来团队小伙伴为社区提供了二十余个主要的 patch,包含 Loop Interchange,以及相关的 dependence analysis、loop cache analysis、delinearization 等分析和优化的增强。简单举几个例子:
- D114916 [LoopInterchange] Enable loop interchange with multiple outer loop indvars ( https://reviews.llvm.org/D114916)
- D114917 [LoopInterchange] Enable loop interchange with multiple inner loop indvars ( https://reviews.llvm.org/D1149167)
这两个 patch 将 Loop Interchange 的应用场景扩展到内层或者外层循环中包含不止一个 induction variable 的情况:
for (c = 0, e = 1; c + e < 150; c++, e++) {
d = 5;
for (; d; d--)
a |= b[d + e][c + 9];
}
}- D118073 [IVDescriptor] Get the exact FP instruction that does not allow reordering (https://reviews.llvm.org/D118073)
- D117450 [LoopInterchange] Support loop interchange with floating point reductions (https://reviews.llvm.org/D117450)
这两个 patch 将 Loop Interchange 的应用场景扩展到支持浮点类型的 reduction 计算的场景:
double matrix[dim][dim];
for (j=0;j< dim; j++)
for (i=0;i <dim;i++)
matrix[i][j] += 1.0;D120386 [LoopInterchange] Try to achieve the most optimal access pattern after interchange (https://reviews.llvm.org/D120386)
这个 patch 增强了 Interchange 的能力使编译器能够将循环体 permute 成为全局最优的循环顺序:
void f(int e[100][100][100], int f[100][100][100]) {
for (int a = 0; a < 100; a++) {
for (int b = 0; b < 100; b++) {
for (int c = 0; c < 100; c++) {
f[c][b][a] = e[c][b][a];
}
}
}=>
void f(int e[100][100][100], int f[100][100][100]) {
for (int c = 0; c < 100; c++) {
for (int b = 0; b < 100; b++) {
for (int a = 0; a < 100; a++) {
f[c][b][a] = e[c][b][a];
}
}
}
}D124926 [LoopInterchange] New cost model for loop interchange (https://reviews.llvm.org/D124926)
这个 patch 为 loop interchange 提供了一个全新的,功能更强的 cost model,可以更准确地对 loop interchange 的 profitability 做出判断。
此外,我们还为社区提供了大量的 bugfix 的 patch:
- D102300 [LoopInterchange] Check lcssa phis in the inner latch in scenarios of multi-level nested loops
- D101305 [LoopInterchange] Fix legality for triangular loops
- D100792 [LoopInterchange] Handle lcssa PHIs with multiple predecessors
- D98263 [LoopInterchange] fix tightlyNested() in LoopInterchange legality
- D98475 [LoopInterchange] Fix transformation bugs in loop interchange
- D102743 [LoopInterchange] Handle movement of reduction phis appropriately during transformation (pr43326 && pr48212)
- D128877 [LoopCacheAnalysis] Fix a type mismatch bug in cost calculation
以及其他功能的增强:
- D115238 [LoopInterchange] Remove a limitation in legality
- D118102 [LoopInterchange] Detect output dependency of a store instruction with itself
- D123559 [DA] Refactor with a better API
- D122776 [NFC][LoopCacheAnalysis] Add a motivating test case for improved loop cache analysis cost calculation
- D124984 [NFC][LoopCacheAnalysis] Update test cases to make sure the outputs follow the right order
- D124725 [NFC][LoopCacheAnalysis] Use stable_sort() to avoid non-deterministic print output
- D127342 [TargetTransformInfo] Added an option for the cache line size
- D124745 [Delinearization] Refactoring of fixed-size array delinearization
- D122857 [LoopCacheAnalysis] Enable delinearization of fixed sized array
结语
如果想要尽可能的利用 Loop Interchange 优化,那在书写 C/C++代码时,请尽可能保证每个迭代之间对数组或数列的访问 stride 越小越好;stride 越接近 1,空间局部性就越高,自然 cache 命中率也会更高,在性能数据上也可以拿到更理想的收益。另外,由于 C/C++的存储方式为 Row-major ordering,所以在访问多维数组时,请注意内层循环要为 Column 才能拿到更小的 stride。
参考
[1] https://zhuanlan.zhihu.com/p/455263968
[2] https://valgrind.org/info/tools.html#cachegrind
[3] https://blog.csdn.net/gengshenghong/article/details/7225775
[4] https://en.wikipedia.org/wiki/Loop_interchange
[5] https://johnysswlab.com/loop-optimizations-how-does-the-compiler-do-it/#footnote\_6\_1738
[6] https://blog.csdn.net/PCb4jR/article/details/85241114
[7] https://blog.csdn.net/Darlingqiang/article/details/118913291
[8] https://en.wikipedia.org/wiki/Row-\_and\_column-major_order
[9] https://en.wikipedia.org/wiki/Locality\_of\_reference
加入我们
欢迎加入 Compiler SIG,与大家共同交流学习编译技术相关内容。
openEuler 公众号:https://url.cy/01H5Rs
openEuler 官网:https://www.openeuler.org/zh/
SIG 列表:https://www.openeuler.org/zh/sig/sig-list/
SIG-Compiler: https://gitee.com/openeuler/community/tree/master/sig/Computing






