eBPF introduce
eBPF introduce
eBPF 发展历程
- 1992年:BPF全称Berkeley Packet Filter,诞生初衷提供一种内核中自定义报文过滤的手段(类汇编),提升抓包效率。(tcpdump)
- 2011年:linux kernel 3.2版本对BPF进行重大改进,引入BPF JIT,使其性能得到大幅提升。
- 2014年: linux kernel 3.15版本,BPF扩展成eBPF,其功能范畴扩展至:内核跟踪、性能调优、协议栈QoS等方面。与之配套改进包括:扩展BPF ISA指令集、提供高级语言(C)编程手段、提供MAP机制、提供Help机制、引入Verifier机制等。
- 2016年:linux kernel 4.8版本,eBPF支持XDP,进一步拓展该技术在网络领域的应用。随后Netronome公司提出eBPF硬件卸载方案。
- 2018年:linux kernel 4.18版本,引入BTF,将内核中BPF对象(Prog/Map)由字节码转换成统一结构对象,这有利于eBPF对象与Kernel版本的配套管理,为eBPF的发展奠定基础。
- 2018年:从kernel 4.20版本开始,eBPF成为内核最活跃的项目之一,新增特性包括:sysctrl hook、flow dissector、struct_ops、lsm hook、ring buffer等。场景范围覆盖容器、安全、网络、跟踪等。
eBPF原理及功能介绍
宏观视角
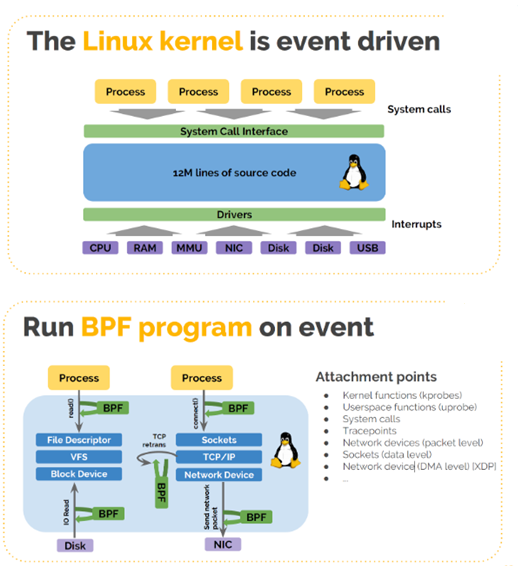
从宏观视角看eBPF,我们将其与kernel进行对比看,便于我们更粗粒度的理解eBPF原理:
- 内核的本质是事件驱动机制,事件由系统调用/系统中断产生。
- eBPF也是事件驱动机制,其采用sandbox技术,与内核隔离。从原理上两者相近,只是能力不同而已。
微观视角
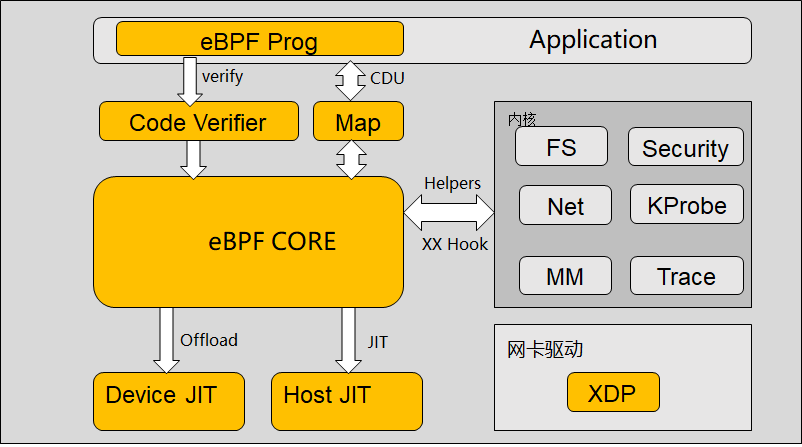
归纳其软件架构特点:
- 采用sandbox技术,旁挂于内核,与用户态应用软件、内核、内核模块(网卡驱动)、Device编程、Host加速等均有交互。
- 通过Helper/hook机制,eBPF与内核可以交换数据/逻辑;通过Map/eBPF Prog机制,eBPF可以与应用程序交换数据/逻辑。最终效果:应用可以通过eBPF改变内核数据/逻辑,或者说用户程序将运行在内核态。
- 用户编程接口:有限能力的高级语言(c/go/rust)编写eBPF Prog。
- 编译方式:通过Clang将其编译成eBPF定义的ISA指令,再由Host/Device JIT翻译成机器指令。
eBPF主要功能介绍
| 特性 | 引入版本 | 功能介绍 | 应用场景 |
|---|---|---|---|
| Tc-bpf | 4.1 | eBPF重构内核流分类 | 网络 |
| XDP | 4.8 | 网络数据面编程技术(主要面向L2/L3层业务) | 网络 |
| Cgroup socket | 4.10 | Cgroup内socket支持eBPF扩展逻辑 | 容器 |
| AF_XDP | 4.18 | 网络原始报文直送用户态(类似DPDK) | 网络 |
| Sockmap | 4.20 | 支持socket短接 | 容器 |
| Device JIT | 4.20 | JIT/ISA解耦,host可以编译指定device形态的ISA指令 | 异构编程 |
| Cgroup sysctl | 5.2 | Cgroup内支持控制系统调用权限 | 容器 |
| Struct ops Prog ext | 5.3 | 内核逻辑可动态替换 eBPF Prog可动态替换 | 框架基础 |
| Bpf trampoline | 5.5 | 三种用途: 1.内核中代替K(ret)probe,性能更优 2.eBPF Prog中使用,解决eBPF Prog调试问题 3.实现eBPF Prog动态链接功能(未来功能) | 性能跟踪 |
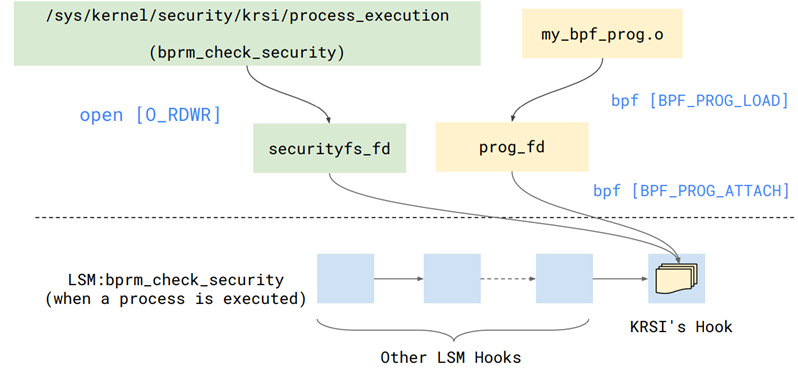
| KRSI(lsm + eBPF) | 5.7 | 内核运行时安全策略可定制 | 安全 |
| Ring buffer | 5.8 | 提供CPU间共享的环形buffer,并能实现跨CPU的事件保序记录。用以代替perf/ftrace等buffer。 | 跟踪/性能分析 |
备注:BPF社区还在快速发展中,众多高级特性可以参考kernel社区。
eBPF应用场景介绍
网络场景
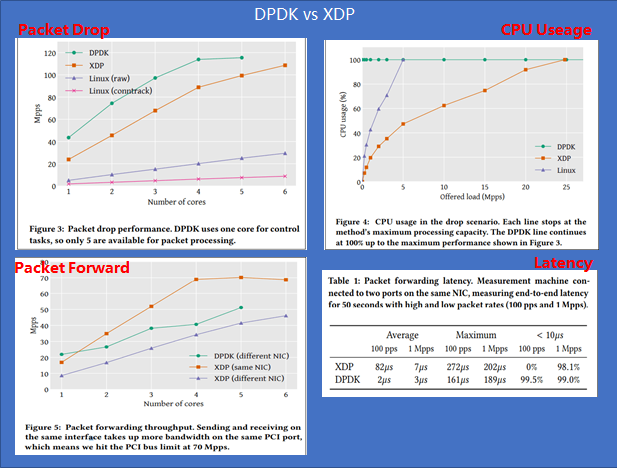
在网络加速场景中,DPDK技术大行其道,在某些场景DPDK成了唯一选择。XDP的出现为厂商提供了一种新的选择,借助于kernel eBPF社区的蓬勃发展,为网络加速场景注入了一股清流。下面我们总结下两种差异:
- [ ] DPDK优势/价值:优势(性能、生态)、价值(带动硬件销售) 性能:总体上XDP性能全面弱于DPDK(但是差距不大),注意:只是比较DPDK/XDP自身性能 生态:DPDK历经多年发展,生态体现在:驱动支持丰富、基础库丰富(无锁队列、大页内存、多核调度、性能分析工具等)、协议支持丰富(社区强大,例如VPP,支持众多协议ARP/VLAN/IP/MPLS等) 价值:将网络类专有硬件的工作转嫁给软件实现,进而拓展硬件厂商市场范围。
- [ ] XDP优势:可编程、内核协同工作 可编程:在网络硬件智能化趋势下,可编程可以适用多种场景。 内核协同:XDP并不是完全bypass kernel,所以在必要的时候可以与内核协同工作,利于网络统一管理、部署。
- [ ] DPDK一些固有缺陷: 独占Device:设备利用率低。 部署复杂:由于独占Device,网络部署需要与OS协议栈协同部署。 开发困难:DPDK定位就是网络数据面开发包,所以它对使用者要求具备专业网络知识、专业硬件知识,所以入门门槛高。 端到端性能不高:DPDK只是提供数据包从NIC到用户态软件的零拷贝,但是用户态传输协议依然需要CPU参与。所以端到端性能不高。
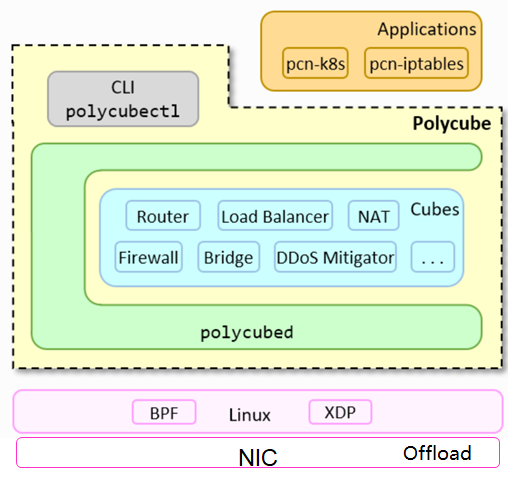
Polycube项目介绍
- [ ] Polycube项目目标是: 重构网络数据面,通过XDP技术实现bypass内核的网络数据面。 北向提供可编程接口,实现网络可编程的事实标准,可被不同解决方案集成(包括网络安全场景、容器场景、虚拟网络场景等)。 南向可以逐步实现硬件offload,便于适配各种智能网卡。
- [ ] Polycube使用场景包括: VNF场景 容器网络数据面 通用网络基础设施(包括iptables、lvs、nat等等) …
VNF场景示例:
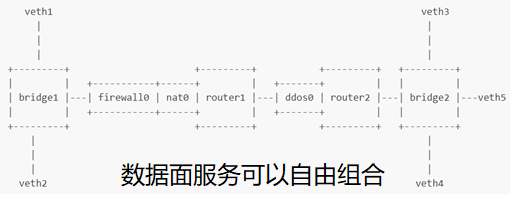
容器场景
背景:云原生场景中容器比虚拟化技术有着更好的低底噪、轻便、易管理等优点,基本已经成为云原生应用的事实标准。容器场景对网络需求实际是应用对网络的需求,即面向应用的网络服务。
- [ ] 云原生应用特点以及对网络的诉求: 生命周期短:要求提供基于PoD静态身份信息实施的网络安全策略。(不能基于IP/Port) 租户间隔离:要求提供API级别的网络隔离策略。 ServiceMesh拓扑管理:要求提供side-car加速。 服务入口位置透明:要求提供跨集群Ingress服务能力。 安全策略跨集群:要求网络安全策略能够在集群间共享、继承。 服务实例冗余保证高可用性:要求提供L3/4层LB能力。
Cilium项目介绍
Cilium 是一个纯开源软件,该软件用于透明地保护使用 Linux 容器管理平台(如 Docker 和 Kubernetes)部署的应用程序服务之间的网络连接。
Cilium 以eBPF作为其技术基础,为容器场景带来高性能、灵活、安全的容器网络解决方案。举例说明其功能:
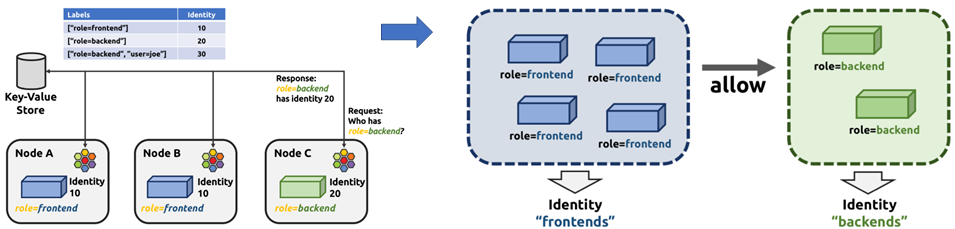
功能1:使用K8S label代替IP/Port作为容器微隔离的标签
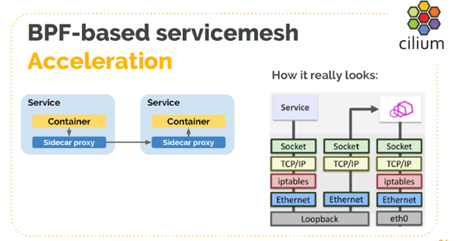
功能2:使用sockmap技术代替loopback环回通信,进而加速side-car
云原生运维场景
背景:容器场景的维测要求与内核提供的维测手段存在相当GAP,虽然内核维测手段种类繁多,但是诸多技术均是站在内核视角提供维测数据,无法支撑容器场景的维测需。 解决方案:采用eBPF技术实现微服务视角的数据采集,实现容器平台的运维功能。行业里面比较成熟的项目sysdig/hubble。
内核逻辑自定义(定制TCP拥塞算法)
参考:https://lwn.net/Articles/811631/
从表现上看,就是BPF可以“任意”重定义内核中struct xxx_ops结构体,5.6版本目前已经支持TCP拥塞算法的定制。
如果使用?
C or rust 语言定义TCP拥塞算法,参考bpf_cubic.c
clang编译拥塞算法成elf文件
bpftool加载elf文件(参考代码struct_ops.c)
~ bpftool struct_ops register <elf>
价值:TCP拥塞算法在CDN这类场景存在大量定制诉求。衍生下,比如file ops,也可以由BPF自定义访问策略。
“Linux内核正在迈向 BPF runtime 微内核方向发展” -- Toke Høiland-Jørgensen
安全场景
背景:Linux系统的运行安全始终是在动态平衡中,系统安全性通常要评估两方面的契合度:signals(系统中一些异常活动迹象)、mitigation(针对signals的一些补救措施)。内核中的signal/mitigation设置散布在多个地方,配置时费时费力。 解决方案:引入eBPF,提供一些eBPF Helper实现“unified policy API”,由API来统一配置signal和mitigation。
eBPF趋势及其背后动机
应用场景归纳
- Bypass内核:比如网络数据路径的bypass、系统调用bypass。
- 内核逻辑定制:比如安全逻辑的定制、容器安全控制、网络TC定制等
- 内核状态窥探:比如结合特定业务领域运维功能(包括容器、AI、大数据等)
- 改造内核基础设施:比如改造内核协议栈iptables、lvs等
- 性能监控:分布式系统的性能分析等。
- …
发展趋势
- [ ] eBPF技术朝着几个方向发展: eBPF虚机的能力逐渐增强:支持有限循环、支持批量报文处理、支持批量MAP操作能力、支持更多指令数量、支持更大的stack、支持更多种类指令。 开发界面逐渐友好:支持runtime debuging、支持Compile-Once Run-Everywhere、支持更多高级语言lib库。 内核向eBPF开放的窗口逐渐放大:最早支持单向互动kernel->eBPF;后来支持双向互动kernel<->eBPF;最新可以支持重定义内核逻辑。
- [ ] eBPF的应用场景趋势: 网络方面:广泛应用在TC、协议栈加速、安全、硬件offload、虚拟化/容器网络。 系统运维:可生产环境部署的运维系统、可视化运维系统。 其他:文件系统、安全等领域。
- [ ] 行业正在发生的: Intel提出高性能XDP概念,通过网卡预处理携带meta-data,提升XDP性能。 Google提出弹性TrafficShaping概念,使用eBPF技术重新打造高性能网络QoS,旨在解决TC root lock、逐包QoS等固有问题。 CloudFlare提出可编程socket的概念,通过eBPF技术旨在解决百万级链接场景socket操作性能耗时大的问题。 Redhat提出bpfilter项目,通过eBPF技术旨在重新实现iptables,使用户无感知的替换iptables。 VMWare提出ovs-ebpf项目,通过eBPF技术加速OVS。
发展背后动机
- 原因1:内核的设计做了太多的抽象(解决用户态API稳定、硬件差异兼容的问题),而抽象的代价是性能开销大。在硬件性能大幅提升后,这个问题就凸显出来。
- 原因2:内核经过长期发展,代码规模已经超过3千万,代码复杂度高,带来的问题是不易扩展新功能。
- 原因3:内核属于社区开源代码,其发展路径并不受商业公司约束。带来的问题是商业公司在内核上的投入被社区绑定。(google曾经评估重新打造一个内核的代价,旨在代替linux内核)
- eBPF特点:内核逻辑可定制、用户态开发代码、内核状态可窥探正是上述原因的发展结果。 社区活跃厂商: Facebook Cilium Netronome Redhat Google …

总结
我们就用2句话总结吧~
"BPF is eating the world.”-- Marek Majkowski Let’s change the world! -- openEuler and all Geeks
openEuler eBPF落地情况
openEuler LTS版本 kernel 4.19 ,openEuler 创新版本 kernel 5.4。
除了上游社区eBPF特性/Bugfix回合openEuler社区之外,openEuler致力于基于eBPF技术打造开放式高性能数据数据面底座,为下游厂商提供更便捷的业务创新方式。
具体情况请移步openEuler 高性能网络sig交流。






