eBPF Introduction
Development History
- In 1992, Berkeley Packet Filter (BPF) was born to provide a custom packet filtering method (class assembly) in the kernel to improve packet capture efficiency by using tcpdump.
- In 2011, the BPF instructions "just in time" (JIT) were introduced to Linux kernel version 3.2, significantly improving BPF performance.
- In 2014, the extended BPF (eBPF) was introduced to Linux kernel version 3.15, providing functions such as kernel tracing, performance tuning, protocol stack QoS, extended BPF ISA instruction set, high-level programming language (C) support, map mechanism, hydrogen-enhanced localized plasticity (HELP) mechanism, and verifier mechanism.
- In 2016, the eBPF-based eXpress data path (XDP) was supported in Linux kernel version 4.8, further expanding the eBPF application in the network field. Then, Netronome proposed the eBPF hardware offload solution.
- In 2018, BPF type format (BTF) was introduced to Linux kernel version 4.18 to convert BPF objects (prog/map) in the kernel from bytecode to unified structure objects. This facilitated the mapping management between eBPF objects and kernel versions and laid a foundation for eBPF development.
- In late 2018, Linux kernel version 4.20 was released. Since then, eBPF has become one of the most active kernel projects, supporting more new features such as sysctrl hook, flow dissector, struct_ops, lsm hook, and ring buffer in scenarios including containers, security, networks, and tracing.
Principles and Functions
Macro Perspective
From a macro perspective, we compared the eBPF with the kernel to help you understand the eBPF principle at a coarse granularity.
- The kernel is event-driven. Events are system calls or system interrupts.
- eBPF is also event-driven. It runs in a sandbox, so it is isolated from the kernel. They are similar in principle, but have different capabilities.
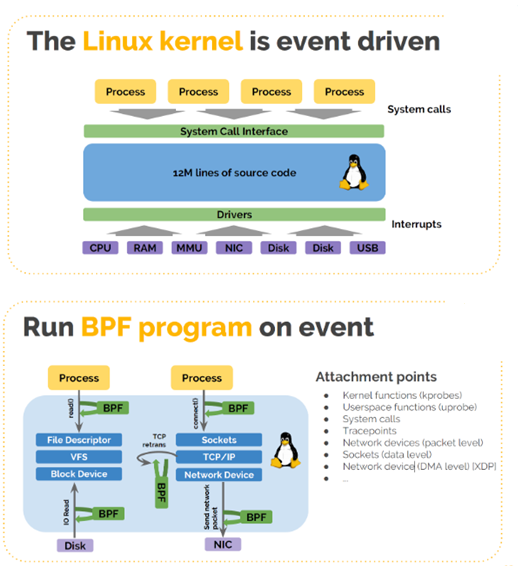
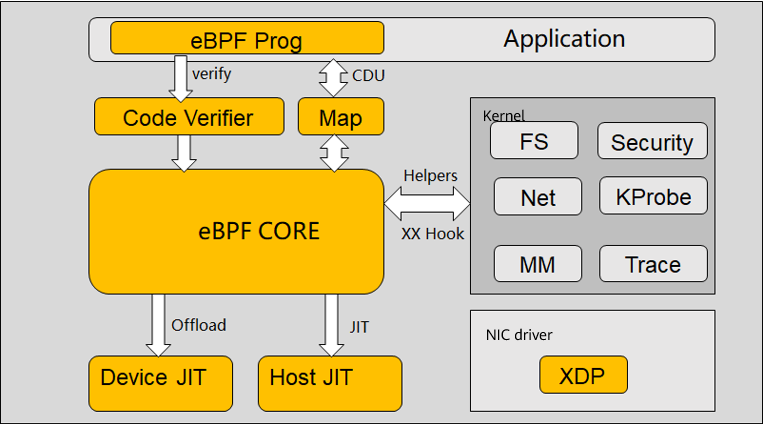
Micro Perspective
The software architecture has the following features:
- eBPF runs in a sandbox that is connected to the kernel in bypass mode, interacting with user-mode application software, kernel, and kernel module (NIC driver) for device programming and host acceleration.
- eBPF exchanges data/logic with the kernel through the helper/hook mechanism and with applications through the map/eBPF prog mechanism. That is, applications can change kernel data/logic through eBPF, and user programs can run in kernel mode.
- eBPF programs are written in high-level languages C, Go, and Rust.
- eBPF programs are compiled to ISA instructions via clang, and then the host/device JIT translates the ISA instructions into machine instructions.
Main Functions
| Feature | First Available In | Function Description | Application Scenarios |
|---|---|---|---|
| Tc-bpf | 4.1 | eBPF reconstructs kernel traffic classification. | Networking |
| XDP | 4.8 | Network data plane programming technology (for L2/L3 services) | Networking |
| Cgroup socket | 4.10 | The socket in the cgroup allows the eBPF logic to be extended. | Container |
| AF_XDP | 4.18 | Original network packets are directly sent to the user mode (similar to DPDK). | Networking |
| Sockmap | 4.20 | Sockmap supports short circuit processing. | Container |
| Device JIT | 4.20 | JIT/ISA decoupling. The host can compile ISA instructions of a specified device form. | Heterogeneous programming |
| Cgroup sysctl | 5.2 | The system invoking permission can be controlled in a cgroup. | Container |
| Struct ops Prog ext | 5.3 | The kernel logic and eBPF Prog can be dynamically replaced. | Framework basics |
| Bpf trampoline | 5.5 | 1. Replaces K(ret)probe in the kernel for better performance. 2. Used in eBPF Prog to solve the eBPF Prog debugging problem. 3. Implements the eBPF Prog dynamic link function (future function). | Performance tracing |
| KRSI (lsm + eBPF) | 5.7 | Customizable security policies during kernel running | Security |
| Ring buffer | 5.8 | A ring buffer is shared between CPUs to provide cross-CPU event order-preserving recording. It is used to replace buffers such as perf and ftrace. | Tracing/Performance analysis |
Note: The BPF community is still developing rapidly. For details about more advanced features, see the kernel community.
Application Scenarios
Networking
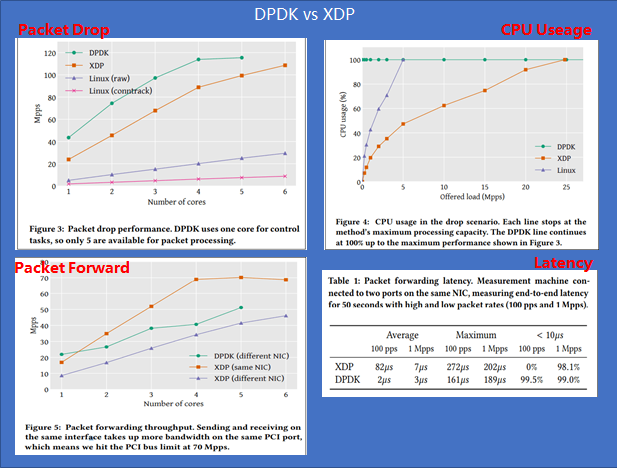
In network acceleration scenarios, DPDK used to be the only choice in some scenarios. With the development of the kernel eBPF community, the emergence of XDP provides a new choice for vendors. The following lists their differences:
- DPDK advantages/values: advantages (performance and ecosystem) and values (driving hardware sales) Performance: Generally, the performance of XDP is slightly weaker than that of DPDK. Note that only the performance of DPDK/XDP is compared. Ecosystem: After years of development, DPDK supports various drivers, base libraries (lock-free queues, huge page memory, multi-core scheduling, and performance analysis tools), and various protocols (for example, ARP/VLAN/IP/MPLS supported by VPP). Value: The work of network dedicated hardware is transferred to software for implementation, expanding the market of hardware vendors.
- XDP advantages: programmability and kernel collaboration Programmability: In the trend of intelligent network hardware, programmability can be applied to multiple scenarios. Kernel collaboration: The XDP does not completely bypass the kernel. It can work with the kernel when necessary to facilitate unified network management and deployment.
- Inherent defects of DPDK: Exclusive device: The device usage is low. Complex deployment: Because devices are exclusively occupied, network deployment requires OS protocol stacks. Difficult development: DPDK is positioned as a network data plane development package. Therefore, users must have professional network and hardware knowledge. Low end-to-end performance: DPDK only provides zero-copy of data packets from the NIC to user-mode software. However, the user-mode transmission protocol still requires the participation of the CPU.
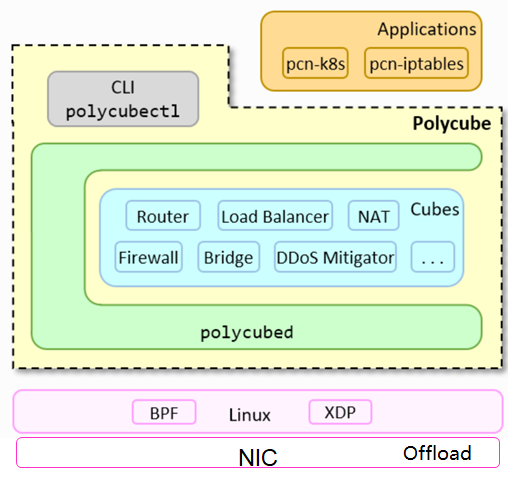
Polycube
- Objectives of the Polycube project: Reconstructing the network data plane and using the XDP technology to bypass the network data plane of the kernel. Providing northbound programmable interfaces to implement de facto standards for network programmability and be integrated by different solutions (including network security scenarios, container scenarios, and virtual network scenarios). Implementing southbound hardware offload to adapt to various iNICs.
- Polycube application scenarios include VNF, container network data plane, and general network infrastructure (including iptables, LVS, and NAT). …
VNF scenario example:
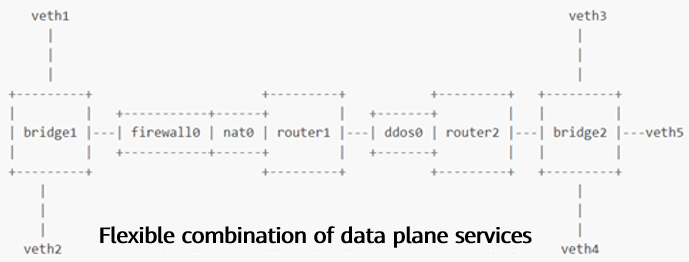
Container
In cloud native scenarios, containers have advantages such as low overhead, light weight, and easy management compared with virtualization technologies. Containers have become the de facto standard for cloud native applications. The network requirements come from actually the applications, that is, application-oriented network services.
- Characteristics of cloud-native applications and network requirements: Short lifecycle: Network security policies must be implemented based on static pod identity information (cannot be based on IP addresses or ports). Tenant isolation: requires API-level network isolation policies. ServiceMesh topology management: requires sidecar acceleration. Transparent service entry: requires the cross-cluster ingress service capability. Cross-cluster security policies: Network security policies must be shared and inherited among clusters. Redundant service instances for high availability: requires layer 3/4 LB capabilities.
Cilium
Cilium is a pure open source software used to transparently protect network connections between applications deployed using Linux container management platforms (such as Docker and Kubernetes).
Cilium uses eBPF as its technical basis to provide a high-performance, flexible, and secure container network solution. The example functions are:
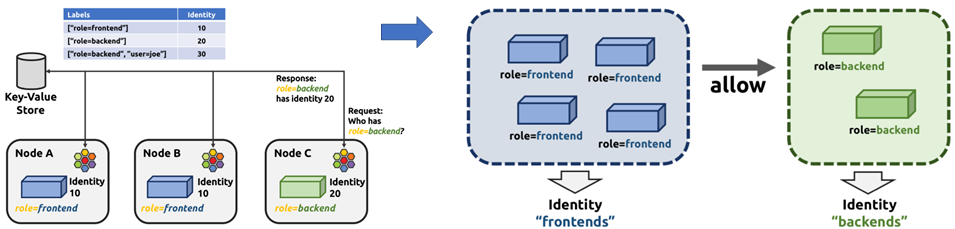
Function 1: Use Kubernetes labels instead of IP addresses/ports for container micro-isolation.
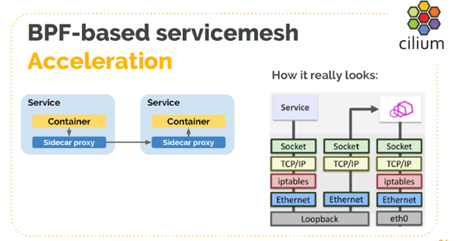
Function 2: Use sockmap instead of loopback for communication to accelerate sidecar.
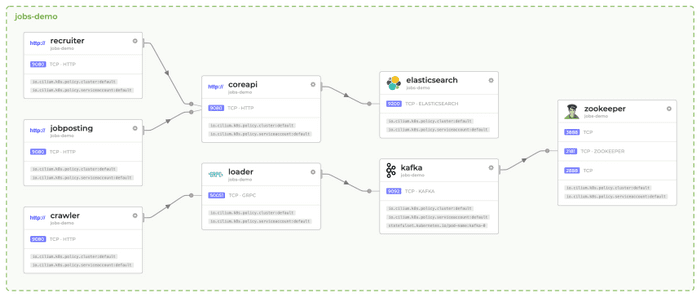
Cloud Native O&M
There are various maintenance and debugging methods in the kernel, but they are provided from the perspective of the kernel and cannot meet the maintenance and debugging requirements in the container scenario. The solution to this is the eBPF technology, which collects data from the microservice perspective and implements the O&M function for the container platform. Mature projects in the industry are sysdig and hubble.
Custom Kernel Logics (Customized TCP Congestion-Control Algorithm)
For details, see https://lwn.net/Articles/811631/
BPF can redefine the struct xxx_ops structure in the kernel. Currently, BPF 5.6 supports the customization of the TCP congestion-control algorithm.
Procedure
Use C or Rust to define the TCP congestion-control algorithm. Refer to bpf_cubic.c for instructions.
Use clang to compile the algorithm into an elf file.
Use bpftool to load the elf file. (Refer to struct_ops.c for instructions.)
~ bpftool struct_ops register \<elf\>
Value: A large number of custom TCP congestion-control algorithms are required in CDN scenarios. For example, BPF can provide custom access policies for file ops.
"The Linux kernel continues its march towards becoming a BPF runtime-powered microkernel" -- Toke Høiland-Jørgensen
Security
The running security of the Linux system is always in dynamic balance. The system security needs to be evaluated from two aspects: signals (indicating abnormal activities in the system) and mitigation (remedial measures for signals). Configuring signals and mitigations scattered in the kernel is time- and labor-consuming. The solution to this is eBPF. It introduces a set of eBPF helpers that provide a unified policy API for signals and mitigations.
Development Trends and Motivations Behind
Application Scenarios
- Kernel bypass: bypass of network data paths and system calls.
- Custom kernel logic: such as security logic, container security control, and network TC
- Kernel status snooping: such as O&M functions in specific service domains (including containers, AI, and big data)
- Kernel infrastructure reconstruction: for example, reconstructing the kernel protocol stack iptables and LVS.
- Performance monitoring: analysis of the performance of the distributed system.
- …
Development Trends
The eBPF technology develops in the following directions: The capabilities of eBPF VMs are gradually enhanced. eBPF VMs support bounded loops, batch packet processing, batch map operations, more instructions, larger stacks, and more types of instructions. The development interface is more user-friendly. It supports runtime debugging, Compile-Once Run-Everywhere, and more advanced language libraries. The window opened by the kernel to the eBPF is gradually enlarged from one-way interaction (from kernel to eBPF) to two-way interaction (between kernel and eBPF). The latest version allows the kernel logic to be redefined.
eBPF application trends: Network: widely used in TCs, protocol stack acceleration, security, hardware offload, and virtualization/container networks. System O&M: O&M system that can be deployed in the production environment and visualized O&M system. Others: file system and security.
Industry news: Intel proposes the concept of high-performance XDP, which uses NIC preprocessing to carry meta-data to improve XDP performance. Google proposes the concept of elastic traffic shaping, which uses the eBPF technology to rebuild high-performance network QoS, aiming to solve inherent problems such as TC root lock and per-packet QoS. CloudFlare proposes the concept of programmable socket. The eBPF technology is used to solve the problem that socket operations are time-consuming in millions of connections. Red Hat proposes the bpfilter project, which uses the eBPF technology to re-implement iptables for perception-free replacement of iptables. VMware proposes the ovs-ebpf project to accelerate OVS using the eBPF technology.
Motivations
- Motivation 1: The kernel design uses too many abstractions to solve the problems of user-mode API stability and hardware incompatibility. The cost of abstraction is high performance overhead. After the hardware performance is greatly improved, this problem becomes prominent.
- Motivation 2: After long-term development, the kernel has more than 30 millions lines of code. The code is complex, making it difficult to expand new functions.
- Motivation 3: The kernel is open source code of the community, and its development path is not restricted by commercial companies. The problem is that the investment in the kernel is bound to the community. (Google once evaluated the cost of rebuilding a kernel to replace the Linux kernel.)
- As a result, eBPF provides features such as customizable kernel logic, user-mode code development, and kernel status snooping. Active vendors in the community include Facebook, Cilium, Netronome, Red Hat, Google…

Summary
This article can be concluded in two sentences.
"BPF is eating the world."-- Marek Majkowski "Let's change the world!"-- openEuler and all Geeks
Implementation of openEuler eBPF
Linux kernel 4.19 of openEuler LTS version and Linux kernel 5.4 of openEuler innovative version.
In addition to inheriting the eBPF and backporting bug fixes of the upstream community, openEuler is committed to building an open, high-performance data foundation based on the eBPF technology to provide downstream vendors with more convenient service innovation methods.
For details, see openEuler High-Performance Network SIG.


